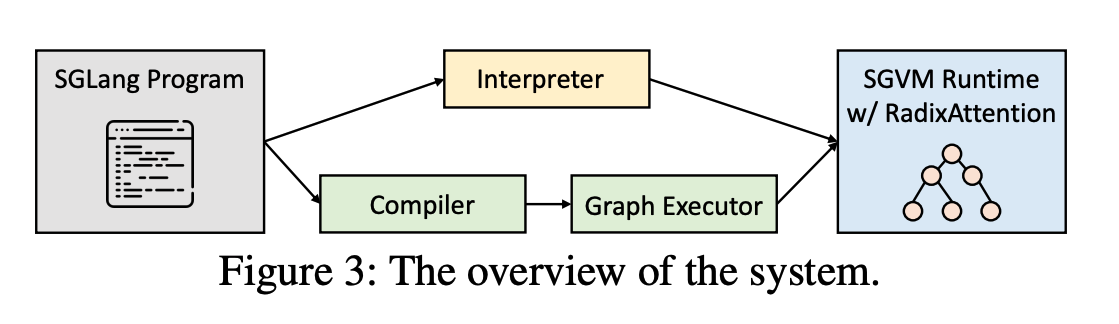
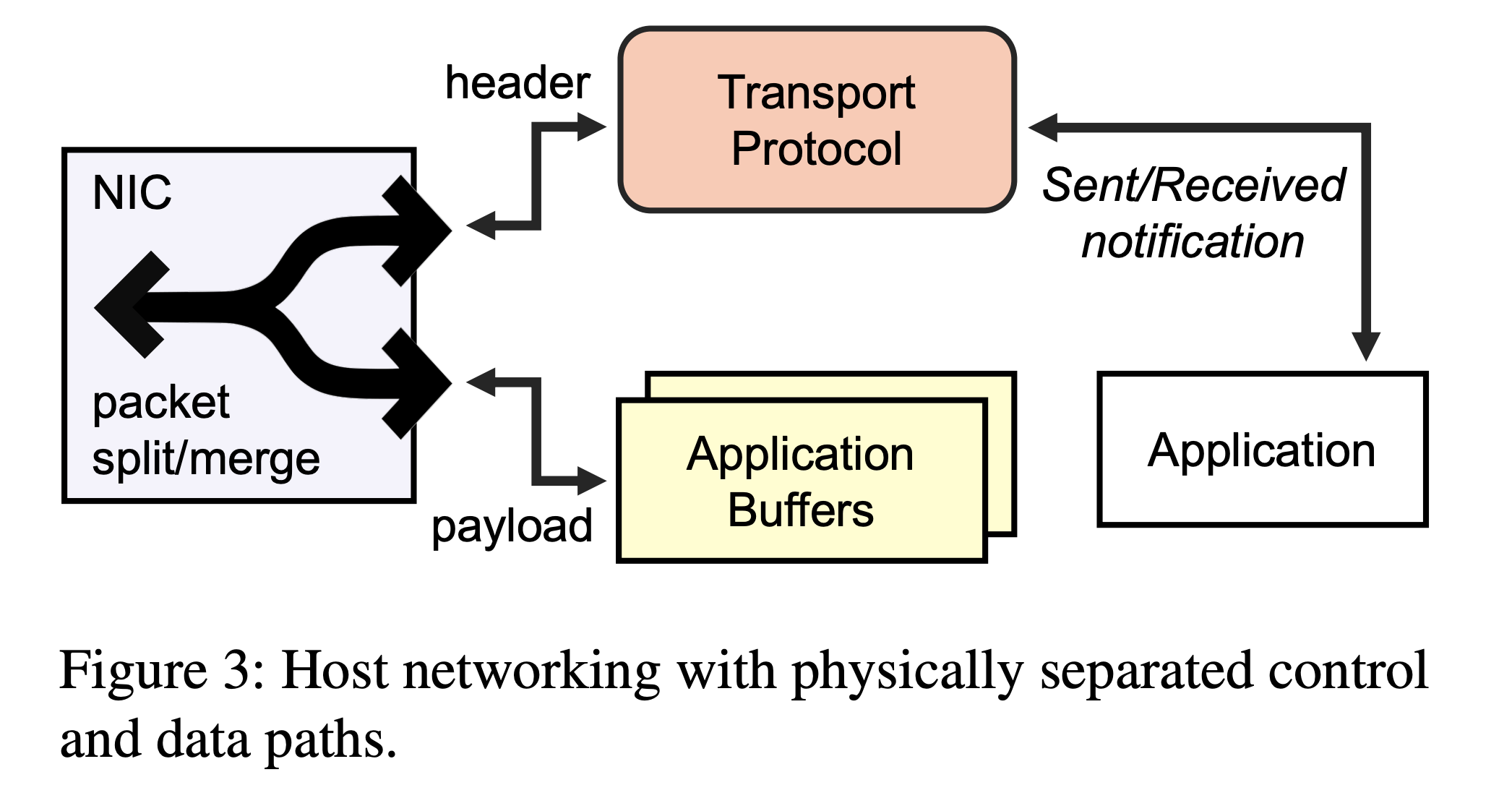
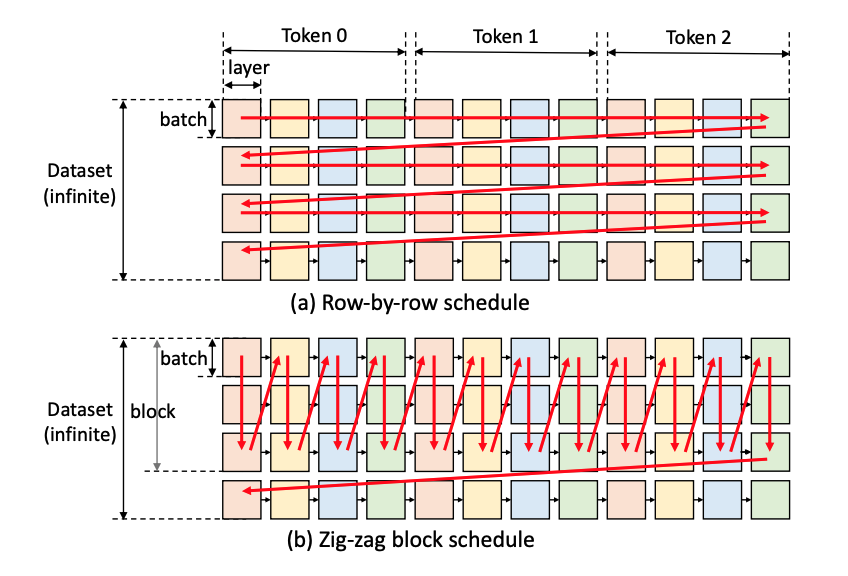
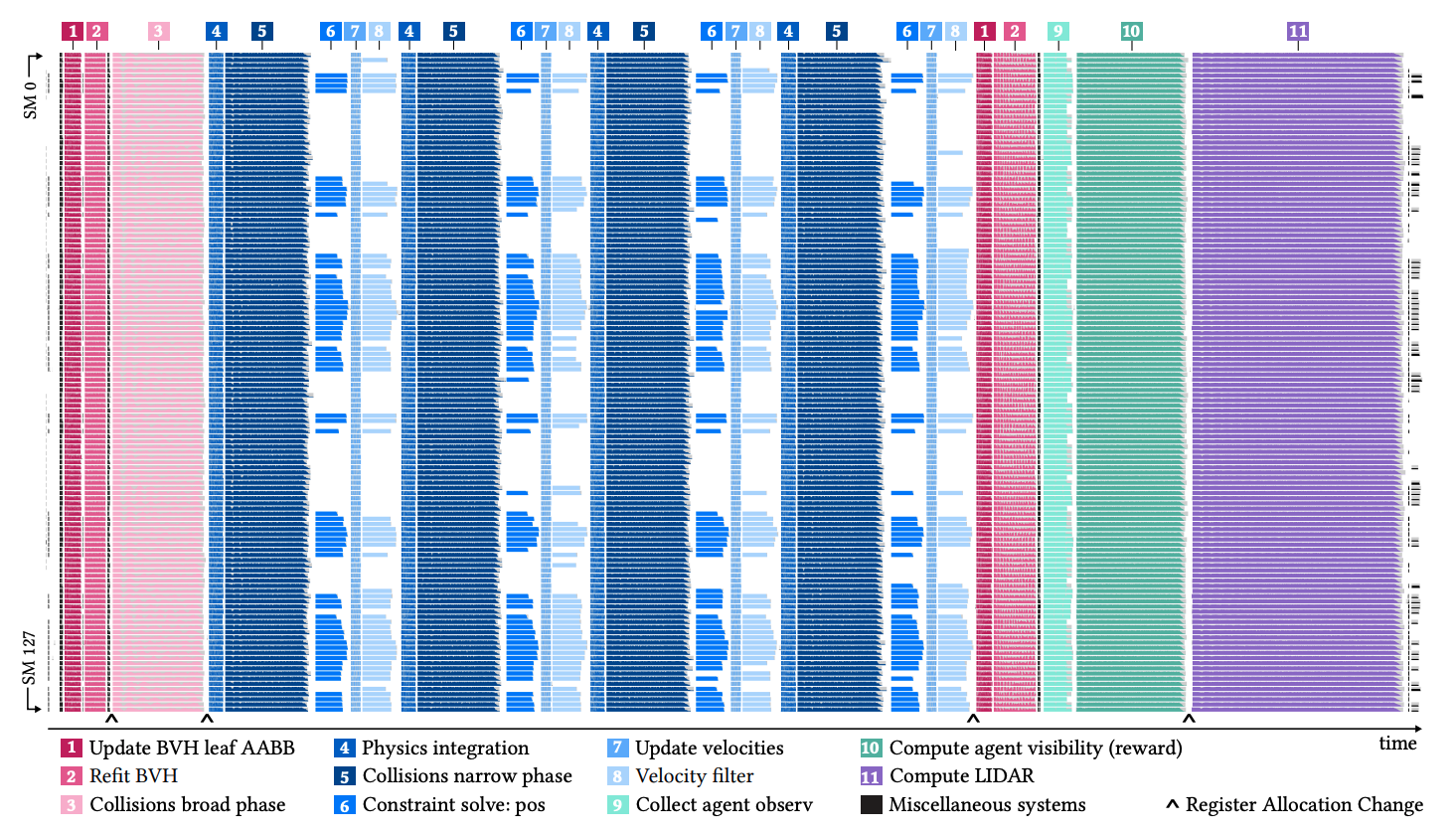
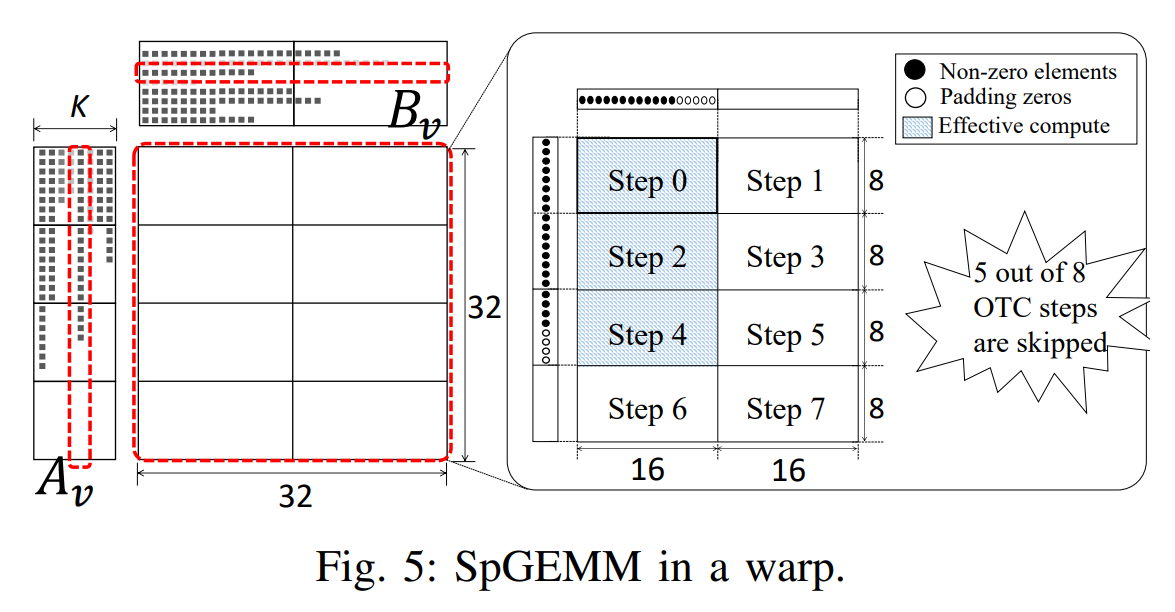
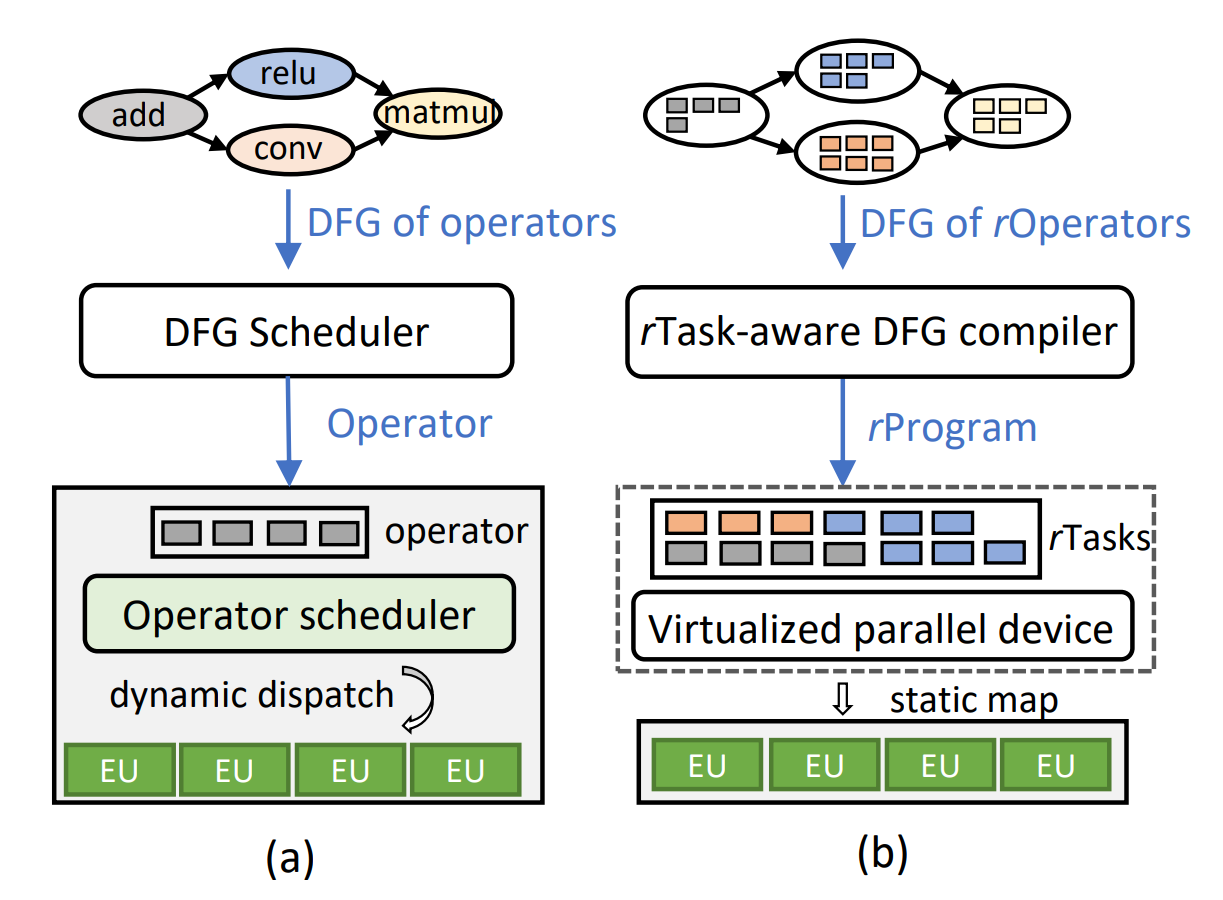
Training AI agents to perform complex tasks in simulated worlds requires millions to billions of steps of experience. To achieve high performance, today’s fastest simulators for training AI agents adopt the idea of batch simulation: using a single simulation engine to simultaneously step many environments in parallel. We introduce a framework for productively authoring novel training environments (including custom logic for environment generation, environment time stepping, and generating agent observations and rewards) that execute as high-performance, GPU-accelerated batched simulators. Our key observation is that the entity-component-system (ECS) design pattern, popular for expressing CPU-side game logic today, is also well-suited for providing the structure needed for high-performance batched simulators. We contribute the first fully-GPU accelerated ECS implementation that natively supports batch environment simulation. We demonstrate how ECS abstractions impose structure on a training environment’s logic and state that allows the system to efficiently manage state, amortize work, and identify GPU-friendly coherent parallel computations within and across different environments. We implement several learning environments in this framework, and demonstrate GPU speedups of two to three orders of magnitude over open source CPU baselines and 5-33\texttimes over strong baselines running on a 32-thread CPU. An implementation of the OpenAI hide and seek 3D environment written in our framework, which performs rigid body physics and ray tracing in each simulator step, achieves over 1.9 million environment steps per second on a single GPU.
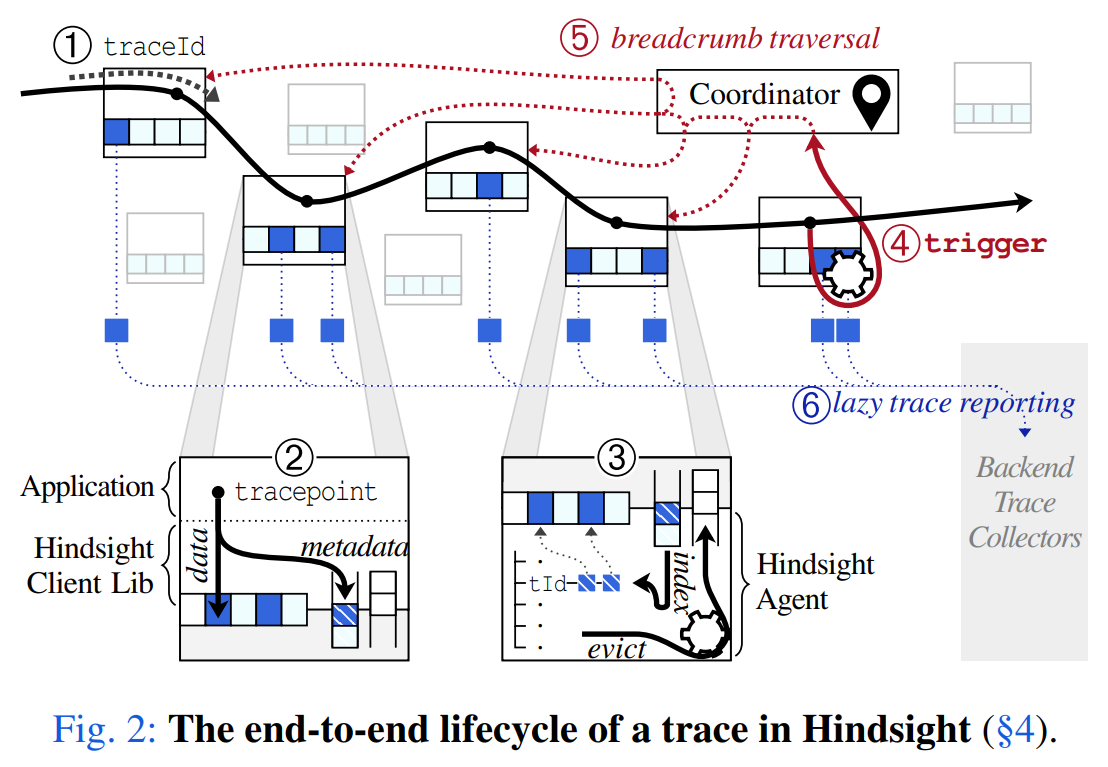
The Benefit of Hindsight: Tracing Edge-Cases in Distributed Systems
Zhang, Lei, Xie, Zhiqiang, Anand, Vaastav, Vigfusson, Ymir, and Mace, Jonathan
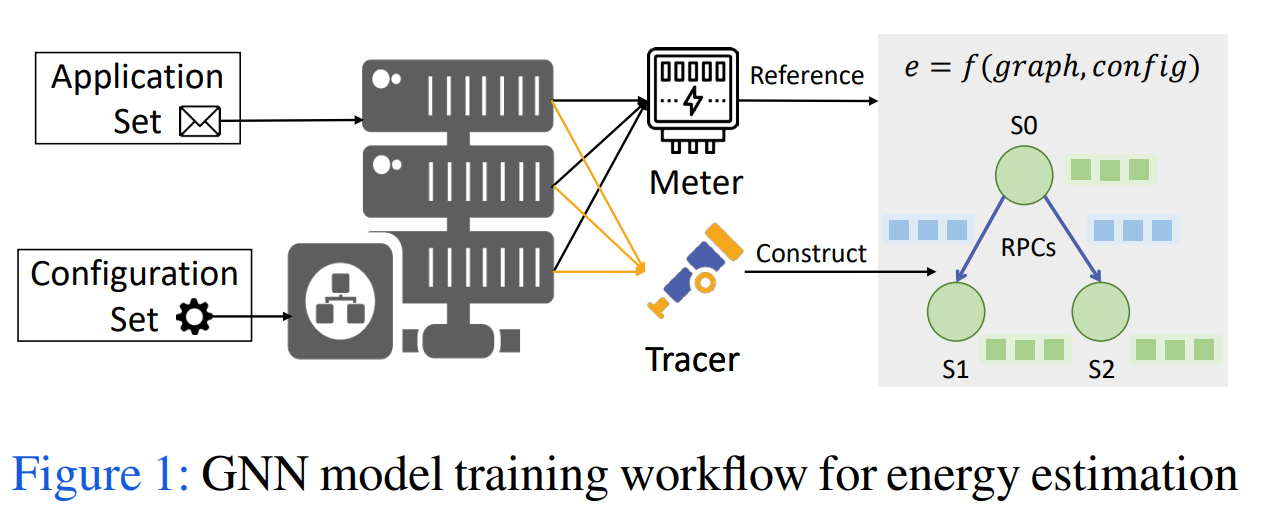
Energy requirements for datacenters are growing at a fast pace. Existing techniques for making datacenters efficient focus on hardware. However, the gain in energy efficiency that can be achieved without making the applications energy-aware is limited. To overcome this limitation, recent work has proposed making the software running in datacenters energy aware. To do so, we must be able to track energy consumption at various granularities at the software level - (i) process level; (ii) application level; (iii) end-to-end request level.Currently, existing software energy-tracking techniques primarily focus on tracking energy at the process or application level; only a few techniques track energy at an end-to-end request level. However, not tracking energy at an end-to-end request level can lead to false software optimizations and cause a decrease in energy efficiency.To track energy at an end-to-end request level, we can leverage end-to-end tracking techniques for other metrics such as distributed tracing. However, we posit that energy cannot be treated as just another metric and that we cannot use existing frameworks without modifications. In this paper, we discuss how energy is different from other metrics and describe an energy-tracking workflow that leverages these differences and tracing techniques in order to track energy consumption of end-to-end requests.
2022
Efficient Flow Scheduling in Distributed Deep Learning Training with Echelon Formation
This paper discusses why flow scheduling does not apply to distributed deep learning training and presents EchelonFlow, the first network abstraction to bridge the gap. EchelonFlow deviates from the common belief that semantically related flows should finish at the same time. We reached the key observation, after extensive workflow analysis of diverse training paradigms, that distributed training jobs observe strict computation patterns, which may consume data at different times. We devise a generic method to model the drastically different computation patterns across training paradigms, and formulate EchelonFlow to regulate flow finish times accordingly. Case studies of mainstream training paradigms under EchelonFlow demonstrate the expressiveness of the abstraction, and our system sketch suggests the feasibility of an EchelonFlow scheduling system.
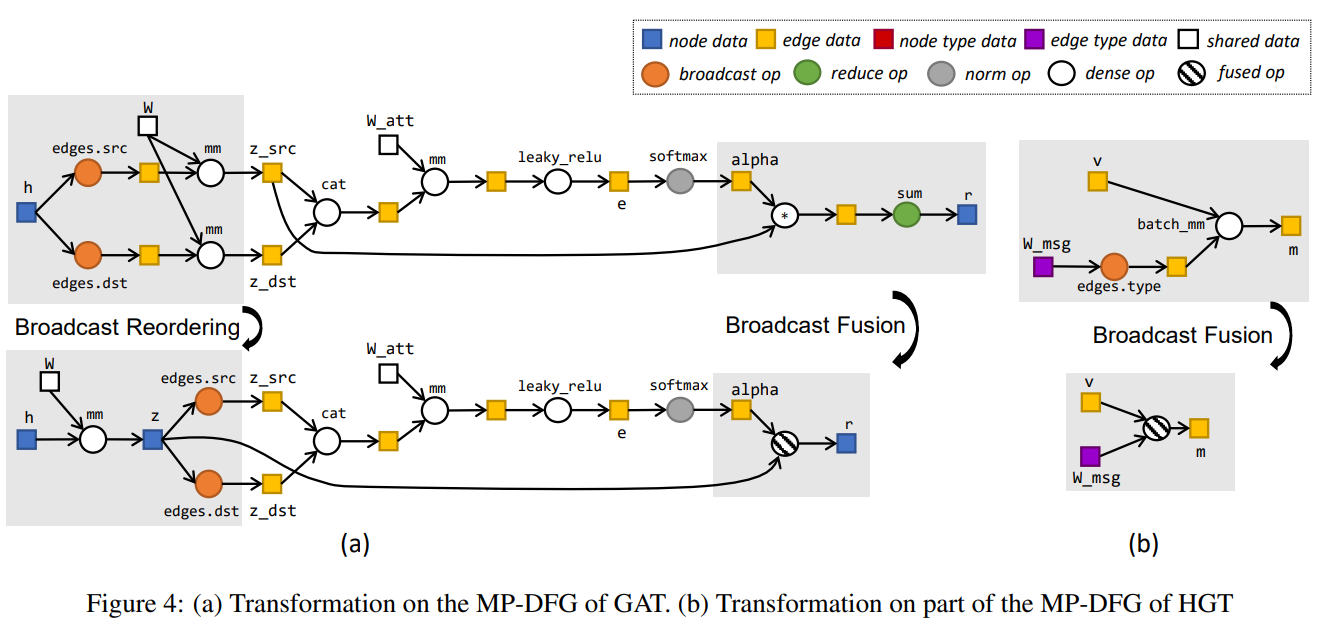
Graphiler: Optimizing Graph Neural Networks with Message Passing Data Flow Graph
Xie, Zhiqiang, Wang, Minjie, Ye, Zihao, Zhang, Zheng, and Fan, Rui
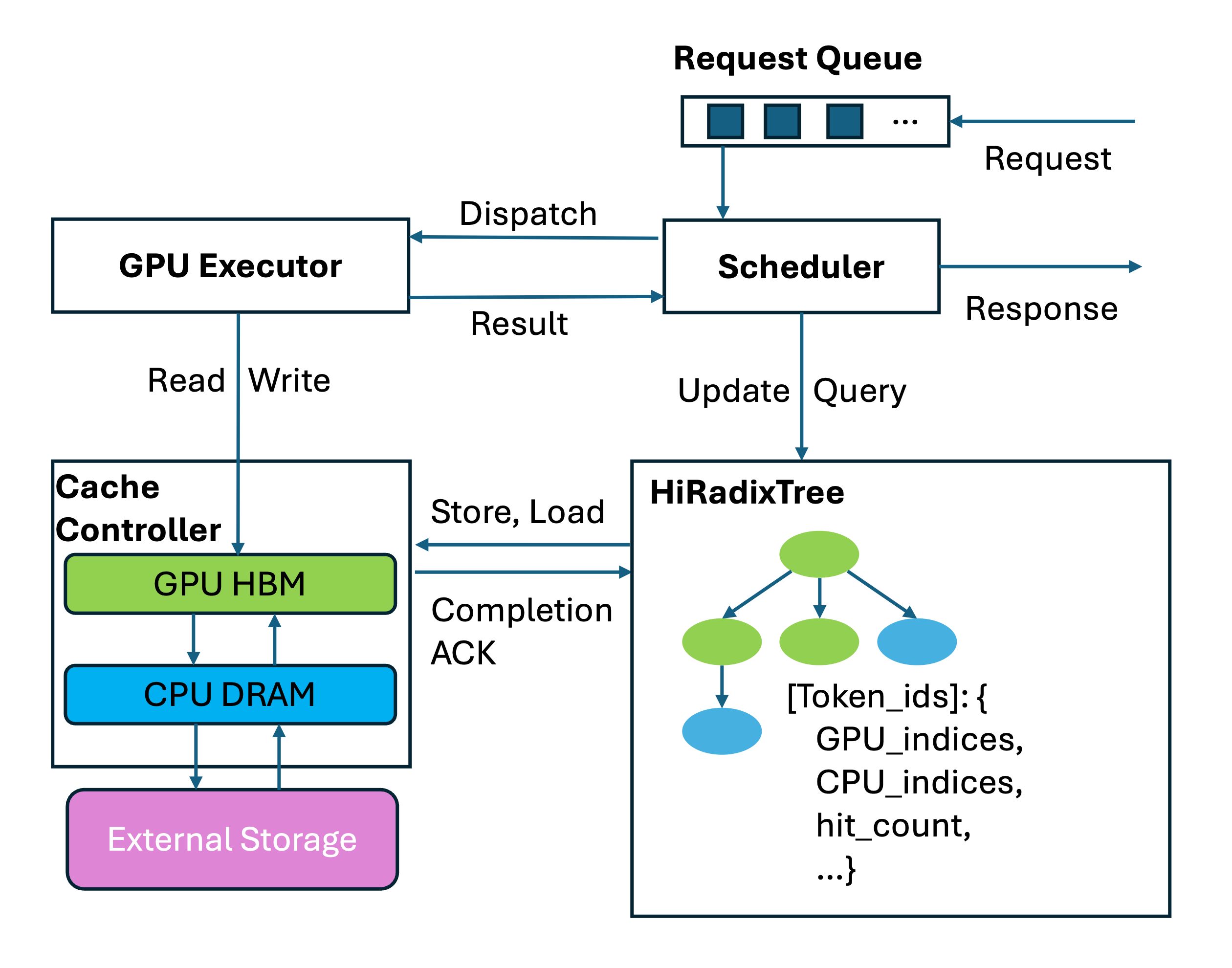

 Cloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight2024
Cloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight2024